Step-by-Step Guide to AI Model Development

In recent years, generative AI has become a hot topic in the tech world. With the emergence of tools like ChatGPT in 2022, the possibilities of generative artificial intelligence have expanded dramatically. This shift is evident in the surge of generative AI usage from 2022 to 2023, opening new doors for data scientists and AI enthusiasts.
Artificial intelligence (AI) models are at the core of modern technological advancements. These models, powered by machine learning algorithms and neural networks, mimic human decision-making processes. They excel in tasks like data analysis, often outperforming humans in accuracy and efficiency. While true sentience remains a distant concept, AI models continue to reshape industries with their analytical prowess and predictive capabilities.
Understanding AI models and their intricacies is essential in navigating the world of artificial intelligence. Unlike traditional machine learning models, AI models go beyond pattern recognition. They delve into complex decision-making and prediction, leveraging vast datasets to provide valuable insights. Developing these models requires a systematic approach, from problem identification to deployment, ensuring that businesses can harness AI's full potential effectively.
In the ever-evolving tech landscape, AI model development stands as a cornerstone of innovation. It fuels the development of AI-powered solutions like AI bots and machine learning algorithms, driving efficiency and transformation across industries. As we delve deeper into AI model development, we unravel the complexities and possibilities that shape the future of AI-driven technologies.
Understanding AI Model Development
AI model development refers to the process of creating and enhancing artificial intelligence systems. It involves designing algorithms, training models, and deploying AI solutions to solve real-world problems. Developers use techniques like Machine Learning, deep learning, and natural language processing to teach AI systems to learn from data, make predictions, and improve over time.
In AI development, researchers and engineers focus on building intelligent systems that can understand, reason, and act like humans in specific domains. This involves coding algorithms, testing them with data, and refining them to achieve desired outcomes. AI development spans various industries, from healthcare and finance to e-commerce and entertainment, driving innovation and efficiency across sectors.
The AI Model Development Lifecycle
AI model development involves multiple stages interconnected to each other. The block diagram below will help you understand every step.
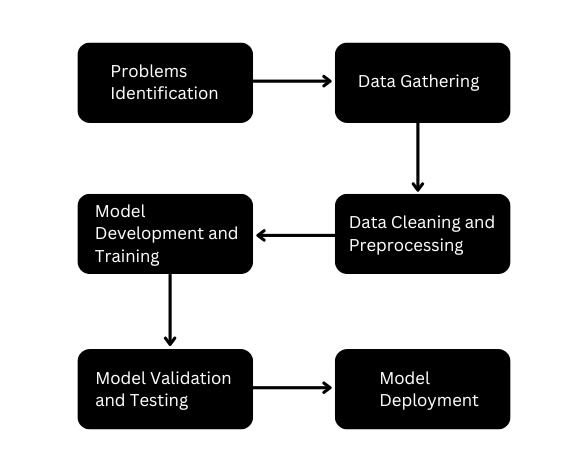
We will now break down each block in detail.
Problem Identification
The first step in AI model development is identifying the problem that needs to be addressed. This stage involves gathering insights from stakeholders, subject matter experts, and end-users to understand the business or domain context comprehensively. Effective problem identification is crucial for ensuring the AI model aligns with intended goals and provides valuable solutions.
During this stage, it's essential to define the specific task or challenge the AI model needs to address, determine the desired outcomes and success criteria, and identify potential real-world implications and impacts of the model's decisions or recommendations. Considering ethical, legal, and regulatory considerations is also important to ensure compliance and responsible development.
Analyzing the limitations of existing solutions and identifying opportunities for innovation through AI techniques is often part of effective problem identification. Clearly defining the problem provides a solid foundation for subsequent stages of model development and helps align stakeholders' expectations.
Data Gathering
The success of an AI model heavily relies on the quality and quantity of the data it is trained on. Data gathering is a critical step that lays the foundation for the model's performance and accuracy.
This process begins with identifying relevant data sources, which can range from structured databases and APIs to unstructured data sources like websites, social media platforms, and sensor data. Evaluating the reliability, quality, and relevance of each data source is essential to ensure the collected data is representative and aligned with the problem being addressed.
Once the data sources are identified, the next step is to acquire and collect the data. This can involve techniques such as web scraping, data extraction from APIs, or leveraging existing datasets. Considering factors like data privacy, security, and compliance with relevant regulations is crucial during this process.
Ensuring data diversity in terms of sources, formats, and representations is another critical aspect of the data gathering phase. AI models trained on diverse and representative data are more likely to generalize well and perform accurately in real-world scenarios.
Data Cleaning and Preprocessing
Data cleaning and preprocessing are essential steps that ensure the data is in a suitable format for model training and address potential issues or biases that could negatively impact the model's accuracy.
Data cleaning involves identifying and addressing various types of data quality issues, such as missing values, inconsistent formats, duplicates, and outliers. These issues can arise from various sources, including human error, sensor malfunctions, or data integration challenges.
Missing values can be handled through techniques like imputation, where missing values are replaced with estimated values based on statistical or machine learning methods. Inconsistent data formats can be addressed through data standardization and normalization processes, ensuring the data adheres to a consistent structure and scale.
Outliers, which are data points that significantly deviate from the norm, can have a substantial impact on model performance. Identifying and handling outliers often involves a combination of statistical techniques, domain knowledge, and expert judgment.
Data preprocessing involves transforming the cleaned data into a format suitable for model training. This step can involve techniques such as feature engineering, encoding categorical variables, and scaling numerical features.
Model Development and Training
The model development and training stage is where the cleaned and preprocessed data is used to build and optimize the AI model itself.
This phase begins with selecting the appropriate machine learning algorithm or model architecture based on the problem at hand, the characteristics of the data, and the desired model performance metrics. Common algorithms and architectures include decision trees, random forests, support vector machines, neural networks (including deep learning architectures), and ensemble methods like gradient boosting.
Once the model architecture is chosen, the next step is to split the available data into training, validation, and test sets. The training set is used to train the model, the validation set for model tuning and hyperparameter optimization, and the test set for final model evaluation.
Model training is an iterative process that involves feeding the training data into the chosen algorithm or model architecture and adjusting the model's parameters to optimize its performance on the validation set. This process is guided by the chosen optimization algorithm and the defined loss or objective function.
Techniques like regularization, dropout, and early stopping may be employed during training to prevent overfitting, where the model becomes too specialized to the training data and fails to generalize well to new, unseen data.
Model Validation and Testing
Model validation and testing are critical steps that ensure the trained model meets the desired performance criteria and can generalize well to new, unseen data.
Model validation involves evaluating the model's performance on a held-out validation set, which was not used during the training process. This step helps identify potential issues like overfitting or underfitting and provides insights into the model's generalization capabilities.
During model validation, various performance metrics are calculated and analyzed to assess the model's effectiveness. These metrics can include accuracy, precision, recall, F1-score, area under the receiver operating characteristic curve (AUROC), and mean squared error, among others.
If the model's performance on the validation set is unsatisfactory, it may be necessary to revisit earlier stages of the development process, such as data cleaning, preprocessing, feature engineering, or model architecture selection.
Once the model has been validated and meets the desired performance criteria on the validation set, it is evaluated on a separate test set. The test set is a held-out portion of the data that has not been used during the training or validation phases. Evaluating the model on the test set provides an unbiased estimate of its performance on new, unseen data, simulating real-world deployment conditions.
Model Deployment
Once the AI model has been thoroughly validated and tested, the next step is to deploy it into a production environment. Model deployment involves integrating the trained model into an application or system where it can make predictions, recommendations, or decisions based on new, real-world data.
Before deploying the model, it's essential to ensure that the deployment environment is properly configured and meets the necessary hardware and software requirements. This may involve setting up cloud infrastructure, containerization, or coordinating with IT teams to provision the required resources.
During the deployment phase, it's crucial to consider factors such as model versioning, scalability, and monitoring. Model versioning ensures different versions of the model can be tracked, managed, and rolled back if necessary. Scalability considerations ensure the deployed model can handle varying workloads and data volumes efficiently.
Monitoring the deployed model's performance is essential for detecting any drift or degradation in its accuracy or behavior over time. This can be achieved through techniques like continuous evaluation, where the model's predictions are regularly compared against ground truth data or human evaluation.
It's also important to establish processes and protocols for updating or retraining the deployed model when necessary, based on changes in the data or business requirements. This may involve periodic retraining or implementing mechanisms for continuous learning and adaptation.
Throughout the deployment phase, it's crucial to maintain security and privacy best practices, especially when dealing with sensitive or regulated data. This may involve implementing access controls, encryption, and auditing mechanisms to ensure the protection of data and model integrity.
Conclusion
As businesses navigate the complexities of AI model development, they embark on a journey of innovation, discovery, and transformation. By harnessing the power of AI bots, machine learning algorithms, and advanced analytics, organizations can unlock new opportunities, drive growth, and shape the future of industries.
At TagX Data, we specialize in AI model development, offering comprehensive solutions tailored to your business needs. From conceptualization to deployment and beyond, we guide you through every stage of the AI model lifecycle, empowering you to harness the full potential of AI and drive meaningful impact.
Are you ready to embark on your AI journey?
Contact us today to learn more about our AI model development services and start transforming your business with AI.
FAQ
Q1: What is AI model development?
AI model development is the process of creating and refining artificial intelligence systems using machine learning algorithms. It involves designing, training, and deploying AI models to solve real-world problems and enhance decision-making processes.
Q2: What is the first step in developing an AI model?
The first step in developing an AI model is problem identification, which involves understanding the problem, defining goals, considering ethical aspects, and aligning with stakeholders' expectations.
Q3: What are the 4 models of AI?
Expert Systems: These AI models use rules and knowledge bases to mimic human decision-making in specific domains, providing expert advice or solving complex problems.
Machine Learning Models: These models learn from data to improve performance over time, including techniques like supervised learning (with labeled data), unsupervised learning (finding patterns in unlabeled data), and reinforcement learning (reward-based learning).
Natural Language Processing (NLP) Models: NLP models process and understand human language, enabling tasks like text analysis, sentiment analysis, language translation, and chatbot interactions.
Computer Vision Models: These models interpret and analyze visual data, such as images or videos, to perform tasks like object detection, image classification, facial recognition, and scene understanding.
Q4: Why is data preparation important in AI model development?
Data preparation is crucial in AI model development as it ensures clean, relevant data for accurate training. Quality data enhances model performance, reduces biases, and leads to more reliable AI outcomes.
Q5: How to Build an AI Model for an Enterprise?
Building an AI model for an enterprise involves the following key steps:
Define the business problem and objectives for the AI model.
Collect, preprocess, and prepare relevant high-quality data from various enterprise sources.
Select the appropriate AI model architecture and algorithm based on the problem type and data characteristics.
Train, tune, and iteratively develop the model using techniques like hyperparameter optimization and cross-validation.
Rigorously evaluate the model's performance, accuracy, and generalization capabilities, ensuring it meets defined objectives without undesirable biases.
Deploy the model into existing enterprise systems, establish processes for monitoring, updating, and maintenance.
Implement robust governance frameworks for responsible and ethical AI use, addressing data privacy, fairness, transparency, and accountability.
Facilitate smooth adoption through change management strategies, user training, and communication plans.
Involve cross-functional teams and stakeholders throughout the process to align the AI model with enterprise goals, culture, and regulatory requirements.
Visit us, www.tagxdata.com


.png)
Comments
Post a Comment